
PROCESS MANAGEMENT
Process - A process is the unit of work in a modern time sharing system . Therefore , a system consist of a collection of process .
EXAMPLE - Operating system process executing system code and used process executing system code and all the process can execute concurrently with the CPU multiplexed amount them .
Program- A process or task is an instance of a program in execution .
It is the smallest unit of whole program . So a no.of process can be present for the execution of a complete program
Difference between process and program :
A process invokes or initiates a program. It is an instance of a program that can be multiple and running the same application.
A process is a program in a state of execution , while a program may have two or more processes running and its always static, it does not have any state........
process is a program in execution,
program is a set of instruction that can be executed on the computer .
Difference Between Process And Program
| Process | Program |
| A process is program in execution | A program is set of instructions |
| A process is an active/dynamic entity | A program is a passive/static entity |
| A process has a limited life span.It is created when execution starts and terminated as execution is finished | A program has a longer life span. It is stored on disk forever |
| A process contains various resources like memory address,disk,printer etc as per requirement | A program is stored on disk in some file. It does not conatin any other resource |
| A process contains memory address which is called address space | A program requires memory space on disk to store all instructions |
States and life cycle of process:
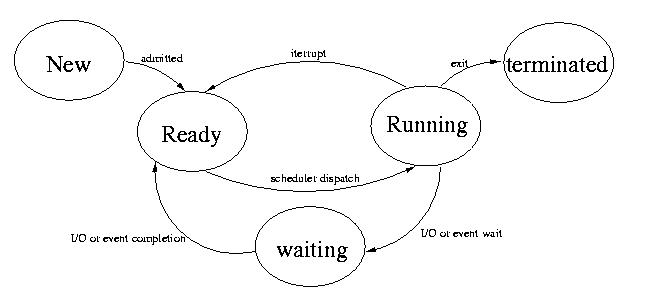
New state:
| S.N. | State & Description |
|---|---|
| 1 |
New state
This is the initial state when a process is first started/created.
|
| 2 |
Ready
The process is waiting to be assigned to a processor. Ready processes are waiting to have the processor allocated to them by the operating system so that they can run. Process may come into this state after Start state or while running it by but interrupted by the scheduler to assign CPU to some other process.
|
| 3 |
Running
Once the process has been assigned to a processor by the OS scheduler, the process state is set to running and the processor executes its instructions.
|
| 4 |
Waiting
Process moves into the waiting state if it needs to wait for a resource, such as waiting for user input, or waiting for a file to become available.
|
| 5 |
Terminated or Exit
Once the process finishes its execution, or it is terminated by the operating system, it is moved to the terminated state where it waits to be removed from main memory.
|
Process control block / Task control block
A Process Control Block is a data structure maintained by the Operating System for every process. The PCB is identified by an integer process ID (PID). A PCB keeps all the information needed to keep track of a process as listed below in the table −
| S.N. | Information & Description |
|---|---|
| 1 |
Process State
The current state of the process i.e., whether it is ready, running, waiting, or whatever.
|
| 2 |
Process privileges
This is required to allow/disallow access to system resources.
|
| 3 |
Process ID
Unique identification for each of the process in the operating system.
|
| 4 |
Pointer
A pointer to parent process.
|
| 5 |
Program Counter
Program Counter is a pointer to the address of the next instruction to be executed for this process.
|
| 6 |
CPU registers
Various CPU registers where process need to be stored for execution for running state.
|
| 7 |
CPU Scheduling Information
Process priority and other scheduling information which is required to schedule the process.
|
| 8 |
Memory management information
This includes the information of page table, memory limits, Segment table depending on memory used by the operating system.
|
| 9 |
Accounting information
This includes the amount of CPU used for process execution, time limits, execution ID etc.
|
| 10 |
IO status information
This includes a list of I/O devices allocated to the process.
|
The architecture of a PCB is completely dependent on Operating System and may contain different information in different operating systems. Here is a simplified diagram of a PCB −

Scheduling:
Scheduling are special system software which handle process scheduling in various ways. Their main task is to select the jobs to be submitted into the system and to decide which process to run. Schedulers are of three types −
- 1.Long-Term Scheduling
- 2.Short-Term Scheduling
- 3.Medium-Term Scheduling
Long Term Scheduling
It is also called a job scheduling. A long-term scheduler determines which programs are admitted to the system for processing. It selects processes from the queue and loads them into memory for execution. Process loads into the memory for CPU scheduling.
The primary objective of the job scheduling is to provide a balanced mix of jobs, such as I/O bound and processor bound. It also controls the degree of multi programming. If the degree of multi programming is stable, then the average rate of process creation must be equal to the average departure rate of processes leaving the system.
On some systems, the long-term scheduling may not be available or minimal. Time-sharing operating systems have no long term scheduling. When a process changes the state from new to ready, then there is use of long-term scheduling.
Short Term Scheduling
It is also called as CPU scheduling. Its main objective is to increase system performance in accordance with the chosen set of criteria. It is the change of ready state to running state of the process. CPU scheduling selects a process among the processes that are ready to execute and allocates CPU to one of them.
Short-term scheduling, also known as dispatchers, make the decision of which process to execute next. Short-term scheduling are faster than long-term scheduling.
Medium Term Scheduling
Medium-term scheduling is a part of swapping. It removes the processes from the memory. It reduces the degree of multi programming. The medium-term scheduler is in-charge of handling the swapped out-processes.
A running process may become suspended if it makes an I/O request. A suspended processes cannot make any progress towards completion. In this condition, to remove the process from memory and make space for other processes, the suspended process is moved to the secondary storage. This process is called swapping, and the process is said to be swapped out or rolled out. Swapping may be necessary to improve the process mix.
Scheduling and performance criteria:
- CPU Utilization − A scheduling algorithm should be designed so that CPU remains busy as possible. It should make efficient use of CPU.
- Throughput − Throughput is the amount of work completed in a unit of time. In other words throughput is the processes executed to number of jobs completed in a unit of time. The scheduling algorithm must look to maximize the number of jobs processed per time unit.
- Response time − Response time is the time taken to start responding to the request. A scheduler must aim to minimize response time for interactive users.
- Turnaround time − Turnaround time refers to the time between the moment of submission of a job/ process and the time of its completion. Thus how long it takes to execute a process is also an important factor.
- Waiting time − It is the time a job waits for resource allocation when several jobs are competing in multiprogramming system. The aim is to minimize the waiting time.
- Fairness − A good scheduler should make sure that each process gets its fair share of the CPU.
Scheduling algorithm-
These are two types of scheduling algorithm:
Non-Preemptive Scheduling
Under non-preemptive scheduling, once the CPU has been allocated to a process, the process keeps the CPU until it releases the CPU either by terminating or by switching to the waiting state.
This scheduling method is used by the Microsoft Windows 3.1 and by the Apple Macintosh operating systems.
It is the only method that can be used on certain hardware platforms, because It does not require the special hardware(for example: a timer) needed for preemptive scheduling.
Preemptive Scheduling
In this type of Scheduling, the tasks are usually assigned with priorities. At times it is necessary to run a certain task that has a higher priority before another task although it is running. Therefore, the running task is interrupted for some time and resumed later when the priority task has finished its execution.
First come first served scheduling algorithm
- Jobs are executed on first come, first serve basis.
- It is a non-preemptive, pre-emptive scheduling algorithm.
- Easy to understand and implement.
- Its implementation is based on FIFO queue.
- Poor in performance as average wait time is high.
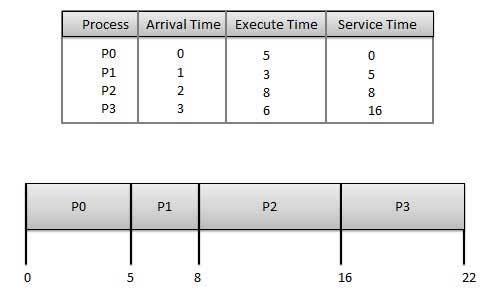 | ||||||||||
GANT CHART ↑
Wait time of each process is as follows −
|
Average Wait Time: (0+4+6+13) / 4 = 5.75
Shortest job first(SJF):
- This is also known as shortest job next, or SJF
- This is a non-preemptive, pre-emptive scheduling algorithm.
- Best approach to minimize waiting time.
- Easy to implement in Batch systems where required CPU time is known in advance.
- Impossible to implement in interactive systems where required CPU time is not known.
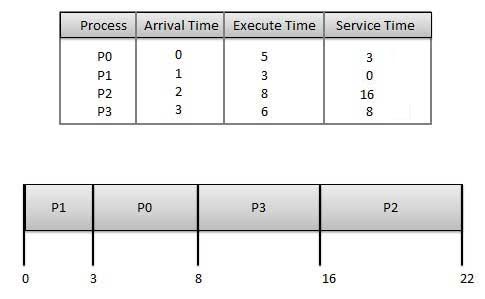
Gant chart ⇑
The processer should know in advance how much time process will take.
Wait time of each process is as follows −
| Process | Wait Time : Service Time - Arrival Time |
|---|---|
| P0 | 3 - 0 = 3 |
| P1 | 0 - 0 = 0 |
| P2 | 16 - 2 = 14 |
| P3 | 8 - 3 = 5 |
Average Wait Time: (3+0+14+5) / 4 = 5.50
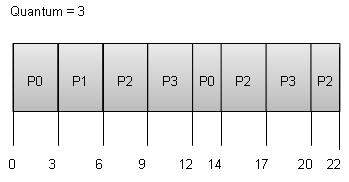
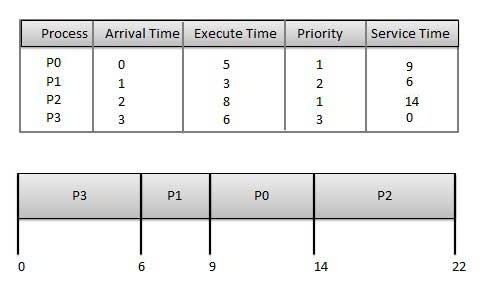
Round robin(RR) scheduling -
- Round Robin is the preemptive process scheduling algorithm.
- Each process is provided a fix time to execute, it is called a quantum.
- Once a process is executed for a given time period, it is preempted and other process executes for a given time period.
- Context switching is used to save states of preempted processes.
Wait time of each process is as follows −
| Process | Wait Time : Service Time - Arrival Time |
|---|---|
| P0 | (0 - 0) + (12 - 3) = 9 |
| P1 | (3 - 1) = 2 |
| P2 | (6 - 2) + (14 - 9) + (20 - 17) = 12 |
| P3 | (9 - 3) + (17 - 12) = 11 |
Average Wait Time:(9+2+12+11) / 4 = 8.5
Priority based scheduling -
- Priority scheduling is a non-preemptive algorithm and one of the most common scheduling algorithms in batch systems.
- Each process is assigned a priority. Process with highest priority is to be executed first and so on.
- Processes with same priority are executed on first come first served basis.
- Priority can be decided based on memory requirements, time requirements or any other resource requirement.
Wait time of each process is as follows −
| Process | Wait Time : Service Time - Arrival Time |
|---|---|
| P0 | 9 - 0 = 9 |
| P1 | 6 - 1 = 5 |
| P2 | 14 - 2 = 12 |
| P3 | 0 - 0 = 0 |
Average Wait Time: (9+5+12+0) / 4 = 6.5
Process synchronization-
Process Synchronization means sharing system resources by processes in a such a way that, Concurrent access to shared data is handled thereby minimizing the chance of inconsistent data. Maintaining data consistency demands mechanisms to ensure synchronized execution of cooperating processes.
Process Synchronization was introduced to handle problems that arose while multiple process executions.
Process synchronization means synchronizing the execution of processes which are trying to access the same data and resources. Whenever multiple processes executes simultaneously, it might happens that they gain access to same resources at same time. This can lead to inconsistency in shared data. Means when a process changes the data, it will not be reflected to other processes which are using it at the same time. To avoid this problem processes are synchronized.
Process synchronization means synchronizing the execution of processes which are trying to access the same data and resources. Whenever multiple processes executes simultaneously, it might happens that they gain access to same resources at same time. This can lead to inconsistency in shared data. Means when a process changes the data, it will not be reflected to other processes which are using it at the same time. To avoid this problem processes are synchronized.
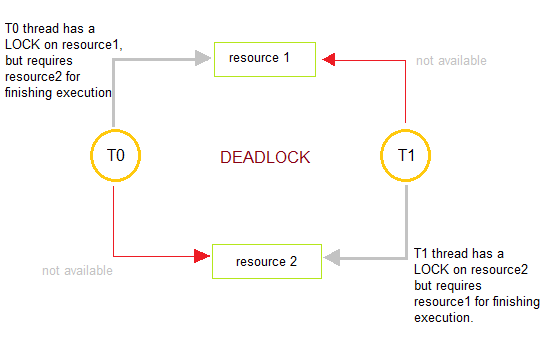
What is a Deadlock?
Deadlocks are a set of blocked processes each holding a resource and waiting to acquire a resource held by another process.
How to avoid Deadlocks
Deadlocks can be avoided by avoiding at least one of the four conditions, because all this four conditions are required simultaneously to cause deadlock.
- Mutual ExclusionResources shared such as read-only files do not lead to deadlocks but resources, such as printers and tape drives, requires exclusive access by a single process.
- Hold and WaitIn this condition processes must be prevented from holding one or more resources while simultaneously waiting for one or more others.
- No PreemptionPreemption of process resource allocations can avoid the condition of deadlocks, where ever possible.
- Circular WaitCircular wait can be avoided if we number all resources, and require that processes request resources only in strictly increasing(or decreasing) order.
Handling Deadlock
The above points focus on preventing deadlocks. But what to do once a deadlock has occured. Following three strategies can be used to remove deadlock after its occurrence.
- PreemptionWe can take a resource from one process and give it to other. This will resolve the deadlock situation, but sometimes it does causes problems.
- RollbackIn situations where deadlock is a real possibility, the system can periodically make a record of the state of each process and when deadlock occurs, roll everything back to the last checkpoint, and restart, but allocating resources differently so that deadlock does not occur.
- Kill one or more processesThis is the simplest way, but it works.
What is a Livelock?
There is a variant of deadlock called livelock. This is a situation in which two or more processes continuously change their state in response to changes in the other process(es) without doing any useful work. This is similar to deadlock in that no progress is made but differs in that neither process is blocked or waiting for anything.
A human example of livelock would be two people who meet face-to-face in a corridor and each moves aside to let the other pass, but they end up swaying from side to side without making any progress because they always move the same way at the same time.
Banker's Algorithm
Banker's algorithm is a deadlock avoidance algorithm. It is named so because this algorithm is used in banking systems to determine whether a loan can be granted or not.
Consider there are n account holders in a bank and the sum of the money in all of their accounts is S. Everytime a loan has to be granted by the bank, it subtracts the loan amount from the total money the bank has. Then it checks if that difference is greater than S. It is done because, only then, the bank would have enough money even if all the n account holders draw all their money at once.
Banker's algorithm works in a similar way in computers. Whenever a new process is created, it must exactly specify the maximum instances of each resource type that it needs.
Let us assume that there are n processes and m resource types. Some data structures are used to implement the banker's algorithm. They are:
Available:It is an array of length m. It represents the number of available resources of each type. IfAvailable[j] = k, then there are k instances available, of resource type Rj.Max:It is an n x m matrix which represents the maximum number of instances of each resource that a process can request. IfMax[i][j] = k, then the process Pi can request atmost k instances of resource type Rj.Allocation:It is an n x m matrix which represents the number of resources of each type currently allocated to each process. IfAllocation[i][j] = k, then process Pi is currently allocated k instances of resource type Rj.Need:It is an n x m matrix which indicates the remaining resource needs of each process. IfNeed[i][j] = k, then process Pi may need k more instances of resource type Rj to complete its task.
Need[i][j] = Max[i][j] - Allocation [i][j]
Resource Request Algorithm:
This describes the behavior of the system when a process makes a resource request in the form of a request matrix. The steps are:
- If number of requested instances of each resource is less than the need (which was declared previously by the process), go to step 2.
- If number of requested instances of each resource type is less than the available resources of each type, go to step 3. If not, the process has to wait because sufficient resources are not available yet.
- Now, assume that the resources have been allocated. Accordingly do,
Available = Available - Requesti Allocationi = Allocationi + Requesti Needi = Needi - Requesti
This step is done because the system needs to assume that resources have been allocated. So there will be less resources available after allocation. The number of allocated instances will increase. The need of the resources by the process will reduce. That's what is represented by the above three operations.
After completing the above three steps, check if the system is in safe state by applying the safety algorithm. If it is in safe state, proceed to allocate the requested resources. Else, the process has to wait longer.
Safety Algorithm:
- Let Work and Finish be vectors of length m and n, respectively. Initially,
Work = Available Finish[i] =false for i = 0, 1, ... , n - 1.
This means, initially, no process has finished and the number of available resources is represented by the Available array. - Find an index i such that both
Finish[i] ==false Needi <= Work
If there is no such i present, then proceed to step 4.It means, we need to find an unfinished process whose need can be satisfied by the available resources. If no such process exists, just go to step 4. - Perform the following:
Work = Work + Allocation; Finish[i] = true;
Go to step 2.When an unfinished process is found, then the resources are allocated and the process is marked finished. And then, the loop is repeated to check the same for all other processes. - If
Finish[i] == truefor all i, then the system is in a safe state.That means if all processes are finished, then the system is in safe state.


No comments:
Post a Comment